




La Fibra Óptica llega a los hogares: el ejemplo de "Mi primera Red FFTH" de Furukawa
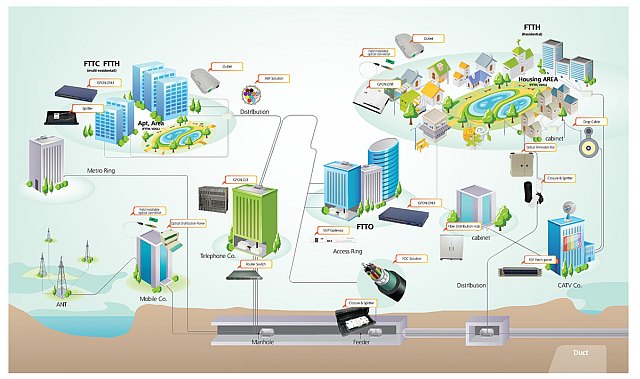
A fines de 2016 se inició el proyecto “Mi primera red FTTH”, diseñado para que las empresas puedan financiar en forma fácil y rápida sus proyectos de tendido de red, accediendo a la mejor tecnología existente en FTTH (Fiber To The Home), con el asesoramiento de expertos de Furukawa y de la mano de un equipo técnico especializado para su implementación.
“Mi Primera Red FTTh” propone una solución “llave en mano” para la implementación de redes de Fibra hasta la casa con tecnología GPON y componentes ópticos de alta calidad, con la garantía y certificación de Furukawa, el diseño, construcción y puesta en marcha en manos de LaRed Net, con certificación en Furukawa y el Concejo FTTH de Latinoamérica (FTTH Council) y, finalmente, el aval de entes financieros locales e internacionales. Éstos hacen posible acercar una solución integral al mercado que está en constante crecimiento producto de la demanda en el acceso Internet por parte de los usuarios.
Bajo esta modalidad, se le presenta a los clientes una propuesta comercial y técnica sobre un módulo de red de 512 Hp, con todos los elementos de la central, red de distribución y terminación. Al momento de la instalación se entregan los primeros 50 kits de instalación para que el cliente pueda iniciar las primeras conexiones en el corto plazo. La campaña contempla una financiación en 12 meses a un 19% anual.
“El foco de los prestadores de servicio, como Cooperativas e ISP, está en optimizar el uso de la infraestructura de red y generar valor sobre la misma ofreciendo mejor acceso a Internet, nuevos contenidos de video, y servicios de infraestructura compartida sobre protocolos IP. Por eso es que en el término de 30 – 45 días, la Campaña propone entregar el final de obra, con el objetivo de poder conectar a los clientes. De esta forma, la comercialización de los nuevos servicios sobre la red de fibra hasta la casa, tiene resultados de corto plazo en cuanto a crecimiento de usuarios, cobertura y facturación por parte de los prestadores”, explica Cristian Ramirez, Key Account Manager para Canales de Furukawa Argentina.
LaRed Net S.A. es una empresa que brinda servicios de Telecomunicaciones desde hace 11 años, y está dedicada a ofrecer servicios de diseño, proyectos, construcción y puesta en marcha de redes de acceso por fibra óptica.
“Hace 4 años somos integradores certificados por Furukawa y desde entonces caminamos el mercado juntos, aportando de ellos toda la línea de materiales pasivos y de fibras ópticas además del apoyo técnico y financiero”, afirma Pablo García, Presidente de LaRed Net S.A. y agrega, “A principios de este año con el cambio de gobierno, al no haber créditos blandos para nuestros clientes (Cooperativas, ISP y cable operadores independientes), creamos en conjunto con Furukawa, LaRed Net, y entes bancarios, una sinergia para llegar aún más a esos clientes que tenían la posibilidad de crecer en su infraestructura pero que no contaban con el apoyo financiero”.
Dentro de esta Campaña, uno de los primeros casos que ya tiene final de obra y pronto comenzará el proceso de instalación de clientes es COPELF-FUTURTEL, Cooperativa de la Ciudad de Las Flores, en Buenos Aires. Allí se realizó un proyecto ejecutivo para ampliar la red de distribución de la cooperativa. Esto permite dar asistencia a barrios donde no llegan los servicios de red de acceso de la cooperativa.
Andrea Costante, Jefa de Área y Coordinadora de Futurtel, comenta que, “luego de un tiempo sin la realización de este tipo de obras, haber concretado esta campaña ha sido realmente un logro para la Cooperativa Eléctrica de Las Flores”.
El proyecto consta de un módulo de 20 manzanas con un proyecto ejecutivo del total de la localidad, e involucra a todos los materiales necesarios desde el cable de fibra óptica, pasivos, activos, sistema de aprovisionamiento, diseño, construcción, hasta la puesta en marcha.
Diego Martín, Gerente Comercial de Furukawa Argentina comenta al respecto de esta Campaña: “Estamos comprometidos con el desarrollo de redes de fibra óptica de mayor calidad en el país. Esta iniciativa es excelente porque hace que todo sea más fácil. Por eso nos sumamos poniendo a disposición a nuestro equipo de expertos y a nuestra tecnología”.
La Fibra Óptica no solo es un factor clave en todos los proyectos de las ciudades inteligentes, sino también es fundamental en lograr el acceso a la conectividad en pequeñas localidades del interior del país como lo demuestra el "Mi primera Red FTTH". Si querés especializarte en esta tecnología con mucha demanda laboral, de la mano de Fundación Proydesa y Furukawa, tenés la posibilidad de hacer el curso que comienza el 19 de abril.
Fast Track: el mejor camino para rendir tu examen de Certificación CCNA
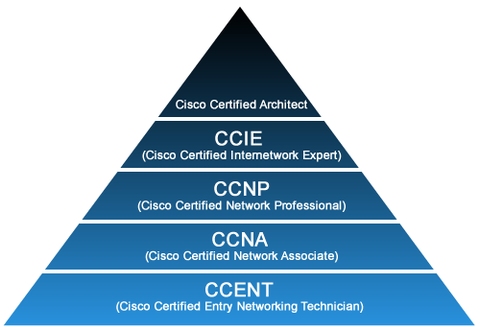
Obtener la Certificación CCNA es el objetivo al que todo especialista en Networking aspira para comenzar su carrera en este fascinante mundo. Por eso hoy vamos a recordar por qué es tan importante en el ámbito laboral:
Según una encuesta de CompTIA, (Employer Perceptions of IT Training and Certification) acerca de qué criterios utilizan los IT Managers a la hora de contratar personal técnico, podemos sacar algunas conclusiones muy interesantes:
Busqueda: 91% de los Managers, con decisión de contratar, consideran la certificación IT como una parte de su criterio de búsqueda de candidatos.
Evaluacion: El 86% de los Managers que tienen decisión de contratar consideran que disponer de certificaciones IT es prioridad alta o media alta durante el proceso de evaluación del candidato.
Verificacion: El 80% de los Directores de RRHH verifican las certificaciones de los candidatos.
Valoracion: 64% de los Managers indican que la puntuación de la certificación es tenida muy en cuenta a la hora de valorar el conocimiento y la experiencia del candidato.
Según un estudio de IDC (Cloud´s Impact on IT Organizations and Staffing), la certificacion, la formación y la experiencia son tres de las cuatro características más importantes que se tienen en cuenta a la hora de contratar un empleado para una posición relacionada con Cloud Computing.
Una encuesta realizada recientemente por la Telecommunications Industry Association, a más de 400 CIOs de todo el mundo, la certificación oficial de Cisco, en sus diferentes variantes: CCNP, CCNA, CCIE,…, sigue estando, en 2017, entre las top certificaciones más demandadas por las empresas, a la hora de buscar ingenieros para sus departamentos IT.
¿Qué beneficios ofrecen las certificaciones para las empresas y los profesionales que las poseen?
Diversos artículos e informes existen en la web que abordan los beneficios de poseer certificaciones tanto para el especialista como para la empresa contratante.
Para la empresa:
- Asegura la competencia técnica de los profesionales de IT al medir de manera precisa los conocimientos y habilidades que posee el trabajador en relación a un perfil laboral.
- El personal es más efectivo y eficiente al momento de culminar las tareas relacionadas con proyectos en networking.
- Se reducen los tiempos para la inducción del personal en las tareas propias de un cargo ya que son más rápidos al momento de adquirir las competencias relacionadas con una labor.
- Garantía de un mejor rendimiento laboral tanto individual como grupal
- Credibilidad en el mercado de trabajo dada por poseer una fuerza laboral de excelencia.
- Reducción en los costos de soporte, ya que el personal capacitado realiza las tareas con mejores resultados y menos necesidad de correcciones. En consecuencia, son más efectivos y eficientes durante la resolución de fallas
- Presentan un mejor desempeño laboral.
- Acredita frente al selector de RRHH que el candidato puede trabajar bajo presión y en situaciones de stress.
En Fundación Proydesa desarrollamos el curso llamado Fast Track, pensado especialmente para todos aquellos que quieren preparse bien para rendir su examen de Certificación CCNA. Se trata de un entrenamiento intensivo a cargo de profesores Certificados que pone énfasis en todos los contenidos teóricos/prácticos, como en las problemáticas del examen.
Comienza el 25 de Octubre. Inscribite aquí.
¿Cuáles son los desafíos que llegan para los especialistas en Redes?

Las Organizaciones que quieran sobrevivir tendrán que ir obligatoriamente hacia lo digital, ya que la digitalización les permitirá ser más ágiles, rápidas y flexibles en su modo de hacer las cosas.
Hoy en día los profesionales necesitan herramientas colaborativas como web conferences, documentos compartidos y pizarras interactivas listas para usar desde cualquier lugar en que se encuentren. Además es imperioso aprovechar el análisis de información en tiempo real.
La Nueva Red
La tendencia explosiva de Internet de las Cosas está reconduciendo la demanda de los especialistas en Redes. Segurizar semejante infraestructura es hoy, más que nunca, un tema crítico, desde el momento en que esos sensores se encuentran fuera del ambiente de Red, como puede ser una flota de autos o una plataforma petroleras offshore, por ejemplo.
Y esto nos enfrenta con una triste realidad: hay pocos profesionales con las habilidades necesarias para estas redes digitales que requieren conocimientos como el control de aplicaciones, virtualización, programabilidad y seguridad y análisis.
Es por esto que los trabajos tradicionales de Networking están evolucionando: administradores de Redes, ingenieros y diseñadores, ahora necesitan considerar tareas como las mencionadas en el párrafo anterior. Como resultado, los profesionales que instalan, operan, orquestan y gestionan las redes digitales deben mantenerse al mismo ritmo que la industria o quedarse atrás. No hay opción.
Sin embargo, aunque estas nuevas destrezas serán esenciales para Redes definidas por Software (SDN) e Internet de las Cosas, coexistirán con la estructura más tradicional de las Redes y el conocimiento de Routing y Switching continuará siendo fundamental.
Cisco Networking Academy adaptó su currícula de CCNA Routing and Switching, pensando en:
- Extender las habilidades de programación a todos los niveles de la empresa. Ya no será necesario sudar configurando un dispositivo por vez. Los Administradores de Redes deben entender cómo utilizar los controladores de provisión.
- Llevar una comprensión básica de la Calidad de Servicio traída desde CCNP, porque la gestión de la Red basada en políticas se basa en un conocimiento completo de la calidad de servicio.
- Aprender como los servicios virtuales coexisten con la infraestructura física
Habilidades en Análisis y Seguridad
Las habilidades y destrezas sobre seguridad ya son fundamentales. Las nuevas amenazas están a la orden del día y las políticas para combatirlas cambian constantemente. Sin embargo, todos estos potenciales riesgos han conducido mejorar las tecnologías de seguridad, y para manejarlas correctamente, los especialistas en networking necesitan mucha capacitación en habilidades como VPNs, firewalls, autenticación y prevención de intrusos.
En este sentido, el conocimiento en análisis de datos también es crítico. Millones de periféricos conectados están creando datos en la Red. Poder recolectar, organizar y refinar esa información, es una inmejorable oportunidad de negocio para las empresas. Por eso las compañías están buscando profesionales con habilidades analíticas que les permitan apropiarse de estas ventajas.
Y estas áreas también están reflejadas en la currícula de CCNA Routing and Switching:
- Aprendizaje de las cuestiones analíticas que apalancan las Redes: configuración, NetFlow, NBAR, y otras fuentes de análisis.
- Reenfoque de las tecnologías VPN para alinearlas con CCIE, CCNP (VPNs de Multipunto Dinámicos –DMVPNs-, VPNs sitio a sitio y clientes VPNs.
- Énfasis en IPv6 por sobre IPv4 para apoyar la migración y adopción corporativa
Las oportunidades seguirán creciendo
Networking es la segunda profesión de más crecimiento en Estados Unidos y en muchas otras partes del mundo. Hacia 2014, el porcentaje de crecimiento en los trabajos relacionados a Redes será superior al resto de todos los trabajos.
Apalancadas por la digitalización, las organizaciones continuarán invirtiendo en tecnologías nuevas, rápidas y móviles; abriendo posibilidades laborales inéditas. La currícula de CCNA Routing and Switching está preparada para enfrentar estos desafíos y prepara profesionales que estén a la altura de las circunstancias.
Nunca ha habido un mejor momento para entrar en este mundo y capacitar a especialistas en estas nuevas habilidades. Es la mejor oportunidad de la historia para aquellos que quieran estar a la vanguardia de lo que la tecnología puede hacer por los negocios y la gente.
Si te sentís parte de los que quieren iniciar su camino en Networking, podés hacerlo de la mano de Fundación Proydesa y Cisco aquí